汇编语言
cpu中储存需要用到的数值地址之类的名叫寄存器(AX,BX,CX诸如此类)。
cpu执行命令是按次序进行的通过cs,ip共同决定cs(段地址),ip(偏移地址)
cs*16+ip便为此次命令的地址,若此次命令并不改变cs或ip,则ip+3或2(由下条命令长度决定)
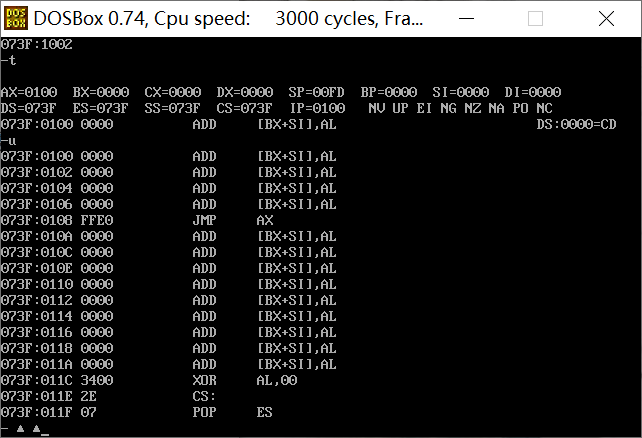
然后执行下次命令。如下图(由左至右CS:IP,指令在十六进制下的表现,指令含义)

工具
Dosbox
常用命令
r命令-展示当前各寄存器值(AX,BX之类)以及当前指向的指令地址(CS,IP)栈地址(SS,SP)
u命令-展示当前指令地址后几行的指令及地址
a命令-修改指定地址所存储的指令(重点是指令)
t命令-执行当前CSIP指向的指令并显示当前哥寄存器值和当前指令地址
d命令-若不输入如d xxxx:xxxx的地址则显示当前指令地址的内存中存储的数据(地址,数据16进制,数据以ASCII码表现状态)
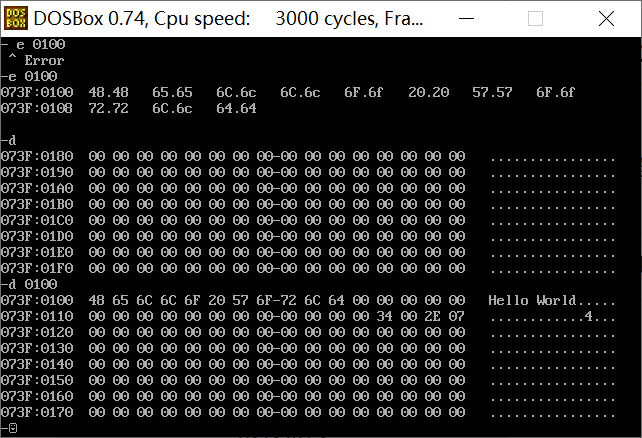
e命令-修改内存中数据(16进制)(如下图实现在内存中写入hello world)
1
2
3
| e 073f:0100
073f:0100 00.48 00.65 00.6c 00.6c 00.6f 00.20 00.57 00.6f 00.72 00.6c 00.64//修改内存
d 0100 //查看0100处内存
|
常用指令
jmp-将cs:ip指向所输入的地址(如 jmp xxxx:xxxx)也可直接调用寄存器中的值(如 jmp ax)
mov-将后项的值赋给前项(注:不能赋给ip)
add-将前项加上后项且和赋给前项
sub-将前项减去后项且差赋给前项
cmp-比较指令,可分为相等,大于,小于:
cmp rsi, rdi相当于 rsi?rdi,”?”可为>.<.=
cmov-条件跳转,分为很多种,但是只要满足对应条件就进行替换
cmova(大于就替换)rdx, rax 大于就将rax赋给rdx
具体指令在CMOV开头的汇编指令 - c++初学者 - C++博客 (cppblog.com)
retn n- 相当于对应跳转
pop eip
add esp, n
stack
{
push-将所给值推入栈
pop-将栈顶值赋给对应寄存器或内存
栈-用来存储指令,地址,等数据,其特点是存储方向由高地址到低地址(windows中)
根据cpu位数不同栈一个栈帧存放不同大小数据(一个字)如16位是2字节,32位4字节,64位8字节
高位地址放高位数据低位地址放低位数据(如16位cpu存放数据高八位存高位地址低八位存低位地址,输入AB则高位是A低位是B)
}
寄存器
通用寄存器
- EAX(寄存器寄存器-累加器):最常用于算术,逻辑和数据传输指令、乘法和除法运算使用此寄存器。对于Windows API函数,函数的返回值通常将存储在EAX寄存器中。
- EBX(基址寄存器):EBX寄存器可以直接访问存储器数据,它也是一个通用寄存器。
- ECX(计数寄存器):ECX是一个共享寄存器,可以用作各种命令的计数器。它还可能包含内存中的数据未对齐。使用计数器的命令是顺序,循环和LOOP / LOOPD指令。
- EDX(数据寄存器):是一个通用寄存器,用于包含乘法结果或除法结果的一部分。它还可以直接访问内存中的数据地址。
- EDI(目标索引):EDI通常用于处理字符串或数组的工作。该寄存器将指向目标字符串。此外它也是一个通用寄存器。
- ESI(源索引):与EDI一样,ESI也经常用于处理字符串或数组的操作。该寄存器将指向源字符串。
- EBP(基本指针):EBP指向内存位置,除了被共享外,还用作访问函数堆栈中的参数和局部变量的帧指针。
- ESP(堆栈指针):该寄存器始终指向当前堆栈顶部。根据堆栈的工作原理,该寄存器将被定向到低位地址。
特殊寄存器
- EIP(指令指针):这是一个特殊的寄存器,它始终指向要执行的下一条指令。与其他寄存器不同,EIP不受指令直接影响。
- EFLAGS(标志寄存器),每个位都是用来反映操作的特定状态,根据计算结果启用这些标志寄存器,并根据这些标志来执行程序的执行分支。
函数调用
call-一般用来调用函数,比如我们在c语言中定义的函数,在父函数(上级函数)call某段函数的起始地址就相当于调用了该函数,配合栈使用ebp,esp,汇编ret命令可以实现子函数再重新调用回父函数
ret-返回上级函数具体则是返回上级函数调用这个命令的下一个命令语句
具体如图
leave
注:
•函数状态主要涉及三个寄存器 —— esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。eip 用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
附:函数具体运行情况(加了百分号就是将前值赋给后值了如mov %esp,%ebp是将esp值赋给ebp)
汇编指令
HeloWorld.exe
1
2
3
4
| .text:00401005 public start
.text:00401005 start proc near
.text:00401005 jmp sub_401010
.text:00401005 start endp
|
public start-用于声明一个函数,其是公用的(可被其他函数调用),其他函数也可类似声明。
start proc near-表示函数开头,此处start表明了是函数入口,对其他的函数来说这个”start”可以换成对应的函数名。
start endp-表示函数结尾,对其他的函数来说这个”start”可以换成对应的函数名。
jmp-jmp sub_401010-运行结果如下
只修改了EIP值相当于指向了第一个函数
1
2
3
4
5
6
7
8
9
| .text:00401010 sub_401010 proc near ; CODE XREF: start↑j
.text:00401010 push 0 ; uType
.text:00401012 push offset Caption ; "D0g3!"
.text:00401017 push offset Text ; "Welcome to Re"
.text:0040101C push 0 ; hWnd
.text:0040101E call MessageBoxA
.text:00401023 push 0 ; uExitCode
.text:00401025 call ExitProcess
.text:00401025 sub_401010 endp
|
当前ip指向push 0,ida常以”;”作注释,搜索后发现其应该是
MessageBox( HWND hWnd, LPCTSTR lpText, LPCTSTR lpCaption, UINT uType)的第一个参数。
push-push 0结果如下
执行此命令后
变为了
将0压入了栈内相当于将栈顶提高了一位(4字节 32bit)
剩下的push都是类似的变化
此处应该都是对MessageBox传参
定义了弹窗类型,传递了字符串的指针,也定义了按钮和图标
这几个push执行后栈内也多了两个字符串的地址和两个数字0
栈顶也被抬高了4位,EIP也向后移动了15
1
2
3
4
| .text:0040101E call MessageBoxA
.text:00401023 push 0 ; uExitCode
.text:00401025 call ExitProcess
.text:00401025 sub_401010 endp
|
。
call-此处call函数将
call函数的下一个指令.text:00401023 push 0 的地址放入了栈中
ESP也因此抬高了一位,EIP指向了所call的函数MessageBoxA的函数头
dword ptr n 就是ESP + n处栈中存取的数据
同时也定义了对应参数在栈内的位置
如dword ptr 4 就是ESP + 4 = 0019FF60 + 4 = 0019FF64
正对应了压入栈中的参数0
其他参数获取原理类似。
offset-__imp_MessageBoxA dd offset user32_MessageBoxA
offset 指令相当于把对应函数“user32_MessageBoxA”的指针(指向函数的头部)给了这个”__imp_MessageBoxA“让其有了等效的作用
所以在上文的jmp中直接jmp到了user32_MessageBoxA这个函数中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| user32.dll:772519E0 user32_MessageBoxA:
user32.dll:772519E0 mov edi, edi
user32.dll:772519E2 push ebp
user32.dll:772519E3 mov ebp, esp
user32.dll:772519E5 cmp dword_77276C94, 0
user32.dll:772519EC jz short loc_77251A10
user32.dll:772519EE mov eax, large fs:18h
user32.dll:772519F4 mov edx, offset unk_772771A4
user32.dll:772519F9 mov ecx, [eax+24h]
user32.dll:772519FC xor eax, eax
user32.dll:772519FE lock cmpxchg [edx], ecx
user32.dll:77251A02 test eax, eax
user32.dll:77251A04 jnz short loc_77251A10
user32.dll:77251A06 mov dword_77276D00, 1
|
mov edi, edi
mov是将后项覆盖给前项,但此处自己覆盖自己是不会改变的
此处这么做的目的在网上搜了一下:
1.为了实现hot-patching技术,即运行时修改一个函数的行为。
2.为了提高效率。执行一条MOV指令比执行两条NOP指令花费更少的时间。
其他的mov指令也是类似的覆盖
push ebp
原来ebp如下图
将EBP的所存的
压入了栈中,抬高了一位ESP
同时EBP中所存的不会因push而被抛弃掉
mov ebp, esp将esp指向的栈顶位置赋给ebp
原ebp
赋值后的ebp
cmp dword_77276C94, 0
将dword_77276c94(0)与0比较
| CMP结果 |
ZF |
CF |
| 目的操作数 < 源操作数 |
0 |
1 |
| 目的操作数 > 源操作数 |
0 |
0 |
| 目的操作数 = 源操作数 |
1 |
0 |
因为相等 所以ZF=1,CF=0但初始状态下ZF=1,CF=0
所以此处ZF,CF值没有变化
jz short loc_77251A10
根据ZF为1就跳转,ZF为0就不跳转
此处在执行cmp dword_77276C94, 0后ZF为1
其会跳转(将EIP移向)short loc_77251A10
1
2
3
4
5
6
7
8
9
10
11
| user32.dll:77251A10 loc_77251A10: ; CODE XREF: user32.dll:user32_MessageBoxA+C↑j
user32.dll:77251A10 ; user32.dll:user32_MessageBoxA+24↑j
user32.dll:77251A10 push 0FFFFFFFFh
user32.dll:77251A12 push 0
user32.dll:77251A14 push dword ptr [ebp+14h]
user32.dll:77251A17 push dword ptr [ebp+10h]
user32.dll:77251A1A push dword ptr [ebp+0Ch]
user32.dll:77251A1D push dword ptr [ebp+8]
user32.dll:77251A20 call near ptr user32_MessageBoxTimeoutA
user32.dll:77251A25 pop ebp
user32.dll:77251A26 retn 10h
|
前面的push为一如既往的传参操作
call也是调用对应的弹窗函数,可见前文有相对应的。
pop ebp
将栈顶的弹出给ebp
原栈顶和ebp:
执行后:
原栈顶的数据并不会被清除只是将栈顶下移了一位
ebp也变为了原栈顶所对应的数据
retn 10h
原ESP和EIP及原栈顶
执行后
相当于将原栈顶的数据弹出给了EIP使得ESP+4h
又让ESP+10h(retn后面所跟的数值)
所以retn n=
C语言
数组
定义数组时 所定义的函数名就相当于地址
如图
定义数组时选择的类型(char int之类)就决定了每个元素对应的长度了
指针
1
2
3
| a='2'
char *pa=&a;
printf("%x %c",pa,*pa)
|
定义时用 类型+*+名字 来表示
这个名字对应的指针变量就存入了一个地址
如果要获取这个地址对应所存取的值则需要在输出时对这个名字加*号
这个操作也叫解引用(获取这个指针变量存入的地址对应的值,相当于按地址寻找值)
当对指针变量+1时则是根据你之前定义指针时的数据类型加对应的地址长度 如char长度为1,int为4
当定义了一个指针指向一个数组名时其实也就是指向了a[0]可通过指针+n后寻找到a[n].
1
2
3
4
| char a[] = { 1,2,3,4,5 };
char* pa = a;
printf("%x,%x",*(pa+1), *pa);
return 0;
|
间接修改及间接引用
*pa=一个值就是对pa指向的值进行间接修改
解引用就是取出对应地址所对的值
位运算
&,|,^,~,<<,>>,>>>
“&”-按位与,都为1时结果是1否则为0
“|”-按位或,有一个为1则为1只有都为0才为0
“^”-异或,相同为0,相异为1
“~”-按位取反,0变1,1变0
“<<”-左移,有符号,会在高位补上符号位,二进制中将低位移向高位
“>>”-右移,有符号,会在高位补上符号位,二进制中将高位移向低位
“>>>”-右移运算符,无符号,左边补0
calloc,malloc
都可用于申请内存一般是用指针来指向所开辟的内存的前项下面举的是calloc的例子 malloc不用说明个数因为callo是分配的连续的内存(类似数组)malloc不一定连续(常出现于链表申请)
数组连续的情况有利于缓存调用(提升程序效率,但降低可修改性,当插入中间值的时候需要修改后面一整个)
链表不连续的情况有利于中间值修改但地址一般大于缓存调用范围(会降低效率但提高可修改性,可修改中间值不用修改后值)
1
2
| int *p=(int *)calloc(开辟个数n,每个的长度(以字节来算)(通常用sizeof()函数));
int *p=(int *)malloc(长度(使用sizeof))
|
HIDWORD,LOWORD取整形的高16位和取整形的低16位
Re工具使用
ida(静态分析)
快捷键
shift+f12 -查看字符串,下侧栏目可以用于搜索
F5(重要)-将汇编代码反编译为类似c语言的伪代码,一般能看懂
alt+b(重要)-寻找字符串 可以进行模糊搜索,但可能字符串被截断搜索不到
alt+t -同样也可寻找字符串
F7-单步步入
F8-单步步过
x-寻找交叉引用,可用于寻找上级函数
Options——Setup Data Types便可选定D时设置的数据类型;
A:可以将图形字符由十六进制数转化成图形,如果一个字节不行,可多选一些字节;
C:将数据转换成代码;
G:跳转至相应的地址处;
Ctrl+F:寻找相应名称的内容;
Shift+F9:打开结构体类型窗口;
在结构体类型窗口中,
Insert(Fn+PgDn得到):创建新的结构体类型;
Delete:删除某一个结构体类型;
在结构体end处,按‘D’便可插入成员变量;
Alt+Q将某个变量转成一个结构体类型,如果代码区有符号变红,说明该地址处原先的也是一个结构体,但后来被其它的定义给覆盖,按两下‘K’即可打散数据;
K:打散数据;
T:将某一符号转成结构体成员变量;
n-修改名字
对于一个函数起始处,D、C、右键——CreateFunction即可还原。
一般有粉红色的都为函数,并非主程序,可以双击键入,使用f5反汇编进入伪代码界面
但一般可能找不到密码所在的位置(可能不叫main函数)可以打开程序观察其输出情况,再用相对应的输出结果搜索相应字符如下图
但一般它可能也不会叫flag,总之根据输出结果寻找对应的函数是大体的解法
下面是找到的对应主程序
可以看到是个将字符串替换的加密 可以双击键入对应数据的初始形态(因为是静态分析,并未实际运行程序使数据加密)
可以将对应函数以及字符串复制下来写入以下代码 得到最终的flag
1
2
3
4
5
6
7
8
9
10
11
12
13
| #include<stdio.h>
int main()
{
char a[30] = { "flag{hacking_for_fun}" };
int i;
for (i = 0; i <= 29; ++i)
{
if (a[i] == 105 ||a[i] == 114)
a[i] = 49;
}
puts(a);
return 0;
}
|
这是最后的输出结果
得到了最终的flag
练题网站BUUCTF在线评测 (buuoj.cn)
补充:ida一般使用时会有缓存文件,相当于做修改只对这些缓存文件进行修改,而不对原文件进行修改,我现在用不到,但一般大型工程需要很久时间,则需要这些保存自己对它做出的修改了
程序脱壳
当用ida静态分析文件时发现函数数特别少一般即为加壳了,可用upx对程序进行脱壳 在powershell中用
1
2
| cd E:\EDGE下载\upx-3.96-win64
upx.exe -d (文件地址和文件名,)//注意文件名中如果带空格可能会被识别成参数或命令 无法正确寻址
|
dump
| 快捷键 |
功能 |
注释 |
| C |
转换为代码 |
一般在IDA无法识别代码时使用这两个功能整理代码 |
| D |
转换为数据 |
|
| A |
转换为字符 |
|
| N |
为标签重命名 |
方便记忆,避免重复分析。 |
| ; |
添加注释 |
|
| R |
把立即值转换为字符 |
便于分析立即值 |
| H |
把立即值转换为10进制 |
|
| Q |
把立即值转换为16进制 |
|
| B |
把立即值转换为2进制 |
|
| G |
跳转到指定地址 |
|
| X |
交叉参考 |
便于查找API或变量的引用 |
| SHIFT+/ |
计算器 |
|
| ALT+ENTER |
新建窗口并跳转到选中地址 |
这四个功能都是方便在不同函数之间分析(尤其是多层次的调用)。具体使用看个人喜好 |
| ALT+F3 |
关闭当前分析窗口 |
|
| ESC |
返回前一个保存位置 |
|
| CTRL+ENTER |
返回后一个保存位置 |
|
有些未含有特征码(特征码被修改),则需要是用dump,直接将实际运行的程序(二进制)记录下来,就起到了脱壳的作用
因为壳会掩盖其实际代码,通过debbugger实际运行会暴露其代码通过以下脚本(偷的)可以获取真实的代码文件(也算是脱壳)
下面为脚本(idc类似于c++)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| #include <idc.idc>
#define PT_LOAD 1
#define PT_DYNAMIC 2
static main(void)
{
auto ImageBase,StartImg,EndImg;
auto e_phoff;
auto e_phnum,p_offset;
auto i,dumpfile;
ImageBase=0x400000;
StartImg=0x400000;
EndImg=0x0;
if (Dword(ImageBase)==0x7f454c46 || Dword(ImageBase)==0x464c457f )
{
if(dumpfile=fopen("D:\\dumpfile","wb"))
{
e_phoff=ImageBase+Qword(ImageBase+0x20);
Message("e_phoff = 0x%x\n", e_phoff);
e_phnum=Word(ImageBase+0x38);
Message("e_phnum = 0x%x\n", e_phnum);
for(i=0;i<e_phnum;i++)
{
if (Dword(e_phoff)==PT_LOAD || Dword(e_phoff)==PT_DYNAMIC)
{
p_offset=Qword(e_phoff+0x8);
StartImg=Qword(e_phoff+0x10);
EndImg=StartImg+Qword(e_phoff+0x28);
Message("start = 0x%x, end = 0x%x, offset = 0x%x\n", StartImg, EndImg, p_offset);
dump(dumpfile,StartImg,EndImg,p_offset);
Message("dump segment %d ok.\n",i);
}
e_phoff=e_phoff+0x38;
}
fseek(dumpfile,0x3c,0);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fseek(dumpfile,0x28,0);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fputc(0x00,dumpfile);
fclose(dumpfile);
}else Message("dump err.");
}
}
static dump(dumpfile,startimg,endimg,offset)
{
auto i;
auto size;
size=endimg-startimg;
fseek(dumpfile,offset,0);
for ( i=0; i < size; i=i+1 )
{
fputc(Byte(startimg+i),dumpfile);
}
}
|
但使用此脚本时首先得找到OEP(程序入口点,真正实现程序功能的入口)
OEP
加壳后会隐藏真正的程序入口点,相当于通过不断地跳转,反复无意义的加减等等(又称作花指令),通过不断地跳转才可以寻找到真正的入口如图下方就是大量的花指令
程序真正运行时往往会进行压栈操作(将函数等数据压入栈中方便执行),而运行结束时会进行出栈操作,可以通过这种特点找到对应的OEP
patch
nop操作
将原花指令(无用的指令)替换为0x90
比如被数据而不是指令所阻碍可以用nop将其连接起来,但是nop并不会修改实际指令所修改的值,所以当某寄存器做出了修改,nop并不能直接替换否则寄存器中的值会与正常运行的值不同,可能会使程序无法正常运行或崩溃,并且nop太多不便于实际分析,所以常用来替代数据.
加密算法
1.异或加密
^ 异或符号,当两个变量A,B异或时其可以看作相对应的bit位分别比较然后进行修改(相同为0,相异为1)如 10010^01110=11100但如果其再次对01110取异或则11100^01110=10010则又变为异或前的值
异或加密可通过如此解密
题目:geek大挑战-(re)-level1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
可通过上文原理解密对应被加密的flag
校验部分可得到对应数据值,但为异或加密后的值需解密
|
具体如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| #include<stdio.h>
int main()
{
char s[] = { 161, 186, 110, 70, 128, 244, 217, 170, 180, 54, 90,
204, 140, 30, 149, 33, 143, 67, 225, 19, 138, 168, 106,
66, 174, 251, 247, 165, 157, 11, 75, 222, 186, 0, 135,
35, 144, 70, 211, 223,'\0'};
char v1 = -85;
int v2 = 0;
v1 = -85;
v2 = 0;
int i, j;
加密时是从前往后加密,则解密需要从后往前解密,需要求出最后的v1对应的值才能做解密运算
将后面的加密顺序调转(包括指令如加密中最后的++v2变为最上方的--v2,异或运算不用变化,只需跟随加密顺序再将顺序逆转就可进行解密运算了
puts(s);
return 0;
}
|
以此就可以得到flag了
base16
base加密算法按分割长度及字典长度不同分为base16,base64等等
base后面的数字指的是它按多少bit划分为一块数据(如base16是以4bit为一块数据,这块数据可以对应2^4个字符类似ascii码,如下图)
| 数据 |
0 |
1 |
2 |
3 |
| 字符 |
‘0’ |
‘1’ |
‘2’ |
‘3’ |
| 数据 |
4 |
5 |
6 |
7 |
| 字符 |
‘4’ |
‘5’ |
‘6’ |
‘7’ |
| 数据 |
8 |
9 |
10 |
11 |
| 字符 |
‘8’ |
‘9’ |
‘A’ |
‘B’ |
| 数据 |
12 |
13 |
14 |
15 |
| 字符 |
‘C’ |
‘D’ |
‘E’ |
‘F’ |
base16可以通过将一个字符数据(8bit)拆分为两部分每个数据对应了上图的(字典)
因为char型只有8bit将字符数据拆分可以通过左移’<<’右移’>>’来实现因为要分别计算,可以通过两个函数来实现拆分
注意1:移位算法计算时,是在所有移位操作完成后才会进行补0操作,如a<<4>>4其值仍然是a,可以通过中间用’b=a<<4;再进行b>>4’
就可以实现b=a的低四位
注意2:移位优先级比加减法要低所以移位时注意加括号
注意3:vs新标准不支持gets,此处fgets效果类似但会将回车(’\n’读入数组内)然后在回车后补空(也是字符串的结束符’\0’)具体指令形式为fgets(字符串数组,字符个数,缓冲区(如stdin))
1
2
3
4
5
6
7
8
9
10
11
12
| #include<stdio.h>
unsigned char base16l(char a)
{
unsigned char b=a>>4;
return b;
}
unsigned char r( char b)
{
unsigned char a;
a=b<<4;
return b >> 4;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| #include<stdio.h>
char r(char m)
{
char b;
b = m<<4;
return b >> 4;
}
int main()
{
char a = r('h');
printf("%d %c",'h', r('h'));
return 0;
}
|
解密环节也可以通过移位操作实现,将高四位和低四位重新拼接起来,如(h<<4+l,以h代指高四位,以l代指低四位)算法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| #include<stdio.h>
char table[] = { "0123456789ABCDEF" };
unsigned char check( char a, char* b)
{
unsigned char c;
for (c = 0; c <= 15; c++)
{
if (a == *(b + c))
{
return c;
}
}
return -1;
}
int main()
{
char jiami[100], jiemi[50], e;
printf("请输入待解密的字符:");
fgets(jiami,100,stdin);
for (a = 0; 1; a++)
{
if (jiami[a] == '\n')
{
jiami[a] = '\0';
break;
}
}
for (b = 0, c = 0; b < a; b += 2, c++)
{
e = check(jiami[b], table) << 4;
jiemi[c] =(e + check(jiami[b + 1], table));
}
jiemi[(a) / 2 -1] = '\0';
puts(jiemi);
}
|
可以将加密与解密拼合起来具体如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| #include<stdio.h>
char table[] = { "0123456789ABCDEF" };
unsigned char r( char m)
{
unsigned char a;
a=m<<4;
return a >> 4;
}
unsigned char l(char n)
{
unsigned char a;
a = n;
return (a>> 4);
}
unsigned char check( char a, char* b)
{
unsigned char c;
for (c = 0; c <= 15; c++)
{
if (a == *(b + c))
{
return c;
}
}
return -1;
}
int main()
{
int flag, a, b, c, f;
printf("选择模式加密0/解密1:");
scanf("%d", &flag);
getchar();
if (flag == 0)
{
{
char yuan[100], jia[200];
printf("请输入待加密的字符:");
fgets(yuan,100,stdin);
for (a = 0; 1; a++)
{
if (yuan[a] == '\0')
{
break;
}
}
for (b = 0, f = 0; b < (2 * a); b += 2, f++)
{
jia[b] = table[l(yuan[f])];
jia[b + 1] = table[r(yuan[f])];
}
jia[2 * a] = '\0';
puts(jia);
}
}
else if (flag == 1)
{
char jiami[100], jiemi[50], e;
printf("请输入待解密的字符:");
fgets(jiami,100,stdin);
for (a = 0; 1; a++)
{
if (jiami[a] == '\n')
{
jiami[a] = '\0';
break;
}
}
for (b = 0, c = 0; b < a; b += 2, c++)
{
jiemi[c] = ((check(jiami[b], table) << 4) + check(jiami[b + 1], table));
}
jiemi[(a) / 2 -1] = '\0';
puts(jiemi);
}
else
printf("输入错误");
return 0;
}
|
也可以自定义字典实现私人的加密解密,但base16只支持16个字符,且加密会将数据量增大一倍
base64
base64原理类似但是其为6bit为一个字符,只有3字符才能完整分为4个字符,所以通过补0来实现解密前与解密后的一一对应
具体如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
|
#include<stdio.h>
#include<stdlib.h>
char zidian[]={"ABCDEFGHIJKMLNOPQRSTUVWXYZabcdefghijkmlnopqrstuvwxyz0123456789+/"};
void base64(char *jiami,int n,char *jiemi)
{
unsigned char a;
int b,c;
if(n%3==0)
{
for(b=0,c=0;b<(n-(n%3));c+=4,b+=3)
{
a=jiami[b]>>2;
jiemi[c]=zidian[a];
a=jiami[b]<<6;
jiemi[c+1]=zidian[(a>>2)+(jiami[b+1]>>4)];
a=jiami[b+1]<<4;
jiemi[c+2]=zidian[(a>>2)+(jiami[b+2]>>6)];
a=jiami[b+2]<<2;
jiemi[c+3]=zidian[a>>2];
}
}
else if(n%3==1)
{
for(b=0,c=0;b<(n-(n%3));c+=4,b+=3)
{
a=jiami[b]>>2;
jiemi[c]=zidian[a];
a=jiami[b]<<6;
jiemi[c+1]=zidian[(a>>2)+(jiami[b+1]>>4)];
a=jiami[b+1]<<4;
jiemi[c+2]=zidian[(a>>2)+(jiami[b+2]>>6)];
a=jiami[b+2]<<2;
jiemi[c+3]=zidian[a>>2];
}
a=jiami[b]>>2;
jiemi[c]=zidian[a];
a=jiami[b]<<6;
jiemi[c+1]=zidian[a>>2];
jiemi[c+2]=zidian[0];
jiemi[c+3]=zidian[0];
}
else
{
for(b=0,c=0;b<(n-(n%3));c+=4,b+=3)
{
a=jiami[b]>>2;
jiemi[c]=zidian[a];
a=jiami[b]<<6;
jiemi[c+1]=zidian[(a>>2)+(jiami[b+1]>>4)];
a=jiami[b+1]<<4;
jiemi[c+2]=zidian[(a>>2)+(jiami[b+2]>>6)];
a=jiami[b+2]<<2;
jiemi[c+3]=zidian[a>>2];
}
a=jiami[b]>>2;
jiemi[c]=zidian[a];
a=jiami[b]<<6;
jiemi[c+1]=zidian[(a>>2)+(jiami[b+1]>>4)];
a=jiami[b+1]<<4;
jiemi[c+2]=zidian[a>>2];
jiemi[c+3]=zidian[0];
}
a=((n-n%3)/3)+1;
jiemi[4*a]='\0';
}
unsigned char found(char jiami)
{
unsigned char a;
for(a=0;a<64;a++)
{
if(jiami==zidian[a])
return a;
}
}
void base64jiemi(char *jiami,int n,char *jiemi)
{
int a,b;
unsigned char c;
for(a=0,b=0;a<n;a+=4,b+=3)
{
jiemi[b]=(found(jiami[a])<<2)+(found(jiami[a+1])>>4);
c=found(jiami[a+1])<<4;
jiemi[b+1]=c+(found(jiami[a+2])>>2);
c=found(jiami[a+2])<<6;
jiemi[b+2]=c+found(jiami[a+3]);
}
}
int main()
{
int n,m,flag;
printf("请选择加密/解密 0/1");
scanf("%d",&flag);
getchar();
if(flag==0)
{
printf("请输入加密长度");
scanf("%d",&n);
getchar();
char *jiami=(char*)calloc(n,sizeof(char));
fgets(jiami,n,stdin);
for(m=0;m<n;m++)
if(jiami[m]=='\n')
{
jiami[m]='\0';
break;
}
char *jiemi=(char*)calloc(4*(((n-n%3)/3)+1)-1,sizeof(char));
base64(jiami,m,jiemi);
puts(jiemi);
}
else if(flag==1)
{
printf("请输入解密长度");
scanf("%d",&n);
getchar();
char *jiami=(char*)calloc(n,sizeof(char));
fgets(jiami,n,stdin);
for(m=0;m<n;m++)
if(jiami[m]=='\n')
{
jiami[m]='\0';
break;
}
char *jiemi=(char*)calloc(m,sizeof(char));
base64jiemi(jiami,m,jiemi);
puts(jiemi);
}
return 0;
}
|
题目(reverse3)-buuctf
先用shift+f12搜索flag
搜索到base64加密字典,猜测是用base64加密完成的
再在左侧通过搜索名称
可以定位到main函数,通过观察输入前的函数
由位运算规律可知sub_4110BE是进行base64加密的,再观察下侧for循环可知进行了移位操作,所以加密逻辑是输入-base64-移位等于最后的str2
对str2进行相反的操作便可
由此得到了最后的flag
RE1.PYC
先启动该文件看下运行结果
不知道是因为什么无法再次运行,通过搜索找到是因为没有原py文件所以无法再次运行,那就通过ida(32位)看看其源代码
pyc文件主要是无法通过f5反汇编查找代码逻辑
尝试通过shift+f12查询字符串,结果如下
一般有效的字符串,线索之类的会出现在此,如果不有效也一般会放在内存附近(一般)
通过双击寻找,往上翻后最终找到了对应的密文(非flag{}此类格式应该是经过了加密)
下方也有说明,表现是通过base64加密的,将其拖入base64中解密
得到了最后的flag:D0g3{Do_You_Want_To_Hammer_Me},这flag真欠揍(bushi)
base58
顾名思义,其字典长度为58个字符,但58无法用位运算得出,效率较低,需通过将字符串按顺序排列,左边的为高位,右边为低位,将其ascii码以十进制一一排列(同样从高到低)用其十进制数连续对58取余再将余数逆序输出就是对应的58进制数(与58字符的字典对应)但此时数字是十分大的,进行大数字运算可能失去精度,可将其转化为文本顺序读取(待做)
加密解密网站:Base58编码/解码 - 一个工具箱 - 好用的在线工具都在这里! (atoolbox.net)
字典为”123456789abcdefghijkmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXYZ”
半成品(如果超过输入7个字符,数据过大,损失精度,无法正常输出):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
| #include<stdio.h>
#include<stdlib.h>
char zidian[] = "123456789abcdefghijkmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXYZ";
static int e=98;
long long int cifang(int a, int n)
{
if (n == 1)
{
return (long long int)1;
}
return (long long int)a * cifang(a, n - 1);
}
long long int zhuanhua10(char* a, int n)
{
if (n == 1)
{
return (long long int) * a;
}
return (long long int)((*(a + n - 1)) + (zhuanhua10(a, n - 1) * 256));
}
long long int zhuanhua58(long long int n, int* p, int* flag)
{
if (*flag == 0)
{
*p = *p + 1;
}
if (n % 58 == 0)
{
if (*flag == 0)
{
*p = *p - 1;
}
return 0;
}
else
return n % 58 + zhuanhua58((long long int)(n - n % 58) / 58, p, flag) * 100;
}
void base58(char* jiami, int n, int* p, char* jiemi, int* flag)
{
int a, b;
long long int c;
c = zhuanhua58(zhuanhua10(jiami, n), p, flag);
for (a = *p, b = 0; a > 0; a--, b++)
{
jiemi[b] = zidian[(c / cifang(100, a)) - (c / cifang(100, a + 1)) * 100];
}
jiemi[b + 1] = '\0';
}
long long int jiaoyan(char a)
{
long long int b;
for(b=0;1;b++)
{
if(a==zidian[b])
{
return b;
}
}
}
long long int huifu10(char *jiami,long long int n)
{
if(n==-1)
{
return 0;
}
return jiaoyan(jiami[n])+huifu10(jiami,n-1)*58;
}
long long int huifu256(long long int n)
{
if(n==0)
{
return 0;
}
return n%256+huifu256((n-n%256)/256)*1000;
}
void base58jiemi(char *jiemi,long long int n)
{
if(n%1000==0)
{
e++;
return;
}
jiemi[e]=n%1000;
e--;
base58jiemi(jiemi,n/1000);
}
int main()
{
printf("请选择加密/解密:0/1");
int n;
scanf("%d",&n);
switch(n)
{
case 0:
{
printf("请输入字符数");
scanf("%d", &n);
getchar();
char* jiami = (char*)calloc(n+2, sizeof(char));
fgets(jiami, n+2, stdin);
int jishu = 0;
int fla = 0;
int* flag = &fla;
int* pjishu = &jishu;
for (n = 0; 1; n++)
{
if (jiami[n] == '\n')
{
jiami[n] = '\0';
break;
}
}
zhuanhua58(zhuanhua10(jiami, n), pjishu, flag);
*flag = 1;
char* jiemi = (char*)calloc(*pjishu + 1, sizeof(char));
base58(jiami, n, pjishu, jiemi, flag);
puts(jiemi);
};break;
case 1:
{
printf("请输入字符数");
scanf("%d", &n);
getchar();
char* jiami = (char*)calloc(n+2, sizeof(char));
fgets(jiami, n+2, stdin);
for (n = 0; 1; n++)
{
if (jiami[n] == '\n')
{
jiami[n] = '\0';
break;
}
}
char jiemi[100]="\0";
jiemi[99]='\0';
base58jiemi(jiemi,huifu256(huifu10(jiami,n-1)));
puts(jiemi+e);
};break;
}
return 0;
}
|
RC4
初始的S表是线性的(如y=x一样是一条直线,第一个元素为1第二个元素为二依次下去)初始密钥填充T表跟S表长度相同一般都为256(此处改为128是因为char在vs,vsc中为signed char 可见字符范围为128)(充当打乱工具,可由初始密钥再生,本质上是初始密钥重复填充如初始密钥123,则T表就为123123……如此循环)再通过打乱的S表生成真正的密钥(用来异或加密)//但同样可能生成不可见字符,打印时会自动隐去,也无法正常输入
解密原理:
若KEY相同则打乱的顺序相同,生成的流密码也相同,通过再次对其进行异或就可以解密了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
| #include<stdio.h>
#include<stdlib.h>
#include<string.h>
int panduanweishu(int a)
{
int b,c;
for(b=1,c=10;1;b++,c*=10)
{
if(a/c==0)
return b;
}
}
void anweitianchongKbiao(int *T,int b,int weishu)
{
int a,c;
for(a=weishu-1,c=10;a>=0;a--,c*=10)
{
T[a]=b%c-b%(c/10);
}
for(a=weishu;a<128;a++)
{
T[a]=T[a%weishu];
}
}
void swap(int *a,int x,int y)
{
a[x]=a[x]^a[y];
a[y]=a[x]^a[y];
a[x]=a[x]^a[y];
}
int main()
{
int S[128],T[128],a,b,c,d,key;
char jiami[100],jiemi[100];
printf("请选择加密或解密 0/1:");
scanf("%d",&a);
getchar();
switch(a)
{
case 0:{
printf("请输入待加密字符");
gets(jiami);
printf("请输入初始KEY");
scanf("%d",&key);
getchar();
for(a=0;a<128;a++)
{
S[a]=a;
}
anweitianchongKbiao(T,key,panduanweishu(key));
for(a=0,b=0;a<128;a++)
{
b=(b+S[a]+T[a])%128;
swap(S,a,b);
}
for(a=0,b=0,c=0;a<strlen(jiami);a++)
{
b=(b+1)%128;
c=(c+S[b])%128;
swap(S,b,c);
d=(S[b]+S[c])%128;
key=S[d];
jiami[a]=jiami[a]^key;
}
puts(jiami);
}break;
case 1:{
printf("请输入待解密字符");
gets(jiami);
printf("请输入初始KEY");
scanf("%d",&key);
getchar();
for(a=0;a<128;a++)
{
S[a]=a;
}
anweitianchongKbiao(T,key,panduanweishu(key));
for(a=0,b=0;a<128;a++)
{
b=(b+S[a]+T[a])%128;
swap(S,a,b);
}
for(a=0,b=0,c=0;a<strlen(jiami);a++)
{
b=(b+1)%128;
c=(c+S[b])%128;
swap(S,b,c);
d=(S[b]+S[c])%128;
key=S[d];
jiami[a]=(unsigned char)jiami[a]^key;
}
puts(jiami);
}break;
return 0;
}
}
|
TEA
此处用了<stdint.h>定义了int16_t,int32_t等带符号整形也有uint8_t,uint16_t等不带符号的整形,u为unsigned的意思
tea加密总体也是用异或加密实现的,且系列算法都通过一个常数作为倍数一般写作0X9E3779B9,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #include <stdio.h>
#include <stdint.h>
void teajiami (uint32_t* v, uint32_t* k)
{
uint32_t sum = 0;
uint32_t v0 = v[0], v1 = v[1];
uint32_t delta = 0x9e3779b9;
uint32_t k0 = k[0], k1 = k[1], k2 = k[2], k3 = k[3];
for (int i=0; i<32; i++)
{
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
}
v[0]=v0;
v[1]=v1;
}
void teajiemi (uint32_t* v, uint32_t* k)
{
uint32_t v0 = v[0], v1 = v[1];
uint32_t delta = 0x9e3779b9;
uint32_t sum = delta * 32;
uint32_t k0 = k[0], k1 = k[1], k2 = k[2], k3 = k[3];
for (int i=0; i<32; i++) {
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
}
v[0]=v0;
v[1]=v1;
}
int main()
{
uint32_t v[2] = {0x12345678, 0x78563412};
uint32_t k[4]= {0x1, 0x2, 0x3, 0x4};
printf("Data is : %x %x\n", v[0], v[1]);
teajiami(v, k);
printf("Encrypted data is : %x %x\n", v[0], v[1]);
teajiemi(v, k);
printf("Decrypted data is : %x %x\n", v[0], v[1]);
return 0;
}
|
XTEA
待做(),跟tea加密类似,都有相同的(&,^,<<,>>)位运算,只不过每次的key是有变化的,但通过观察伪代码应该可以实现辨认
1
2
3
4
5
| for (int i=0; i<32; i++) {
v0 += (((v1 << 4) ^ (v1 >> 5)) + v1) ^ (sum + key[sum & 3]);
sum += delta;
v1 += (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum + key[(sum>>11) & 3]);
}
|
XXTEA
待做(),跟tea加密类似,加密轮数由待加密字符数决定
MD5
md5主要用于校验文件(不同的文件生成的md5码不同,通过检测传输前后的md5码可以检测其是否被篡改)
MD5可以将信息以512位来处理信息
主要是让信息长度比512的整数倍少64位(记录数据长度),若不足则进行填充(由一个一和对应的后续一段0表示)
再将对应的信息分块,每块有512位,再将每块再分为16个32位
用四组幻数进行循环计算(可用于检验是否位为MD5算法)
另外检验MD5算法一般可以看见较长的函数运算语句
仿射密码
和数学上的线性方程类似
可通过a,b(这俩个都为密钥),n(字符个数)
c(密文)=(a*m(待加密字符)+b)(mod n)
此处n的个数就是字典的长度(字典可自定义)
因为要解密所以a与b需互质,这样才能让字符与密文一一对应
则解密算法为
d(解密)=(a-gcd(a,n)(c-b))(mod 26)
gcd为欧几里得算法,取最大公约数